
This article explains how caching works in Document360 applications, rendering fast responses for documentation websites.
Fast websites
Nowadays, the speed is business. If your website doesn’t render fast enough, you’re losing business day by day. Document360 uses In-Memory Cache to render websites faster. When you scale your applications, having another level of caching helps to have had less pressure on the original data source.
Cache
Caching is an act of keeping data in temporary storage to allow retrieval without having to request the data repeatedly from the original data source, reducing the trips to the original data source, in-turn improving the response time. We keep frequently accessed objects, images, and data closer to the requesting client, speeding up access. The word “caching” spans in a lot more different dimensions, but we’re discussing in the context of a request from the browser to an app hosted on a server. Let’s refer to a “database” as an original data source going forward, and “Redis” will remain as the Second-Level cache.
A browser is the first layer of caching. It caches the images and data as configured for the website plus the browser. So that if the data doesn’t change the requested resource would serve back from the browser itself.
Next, the Web-Server has a caching layer typically implemented as In-Memory Cache or Memcache.
In-Memory Caching for web apps works fast and it is one of the must-have components in every web app. In a normal scenario, when you scale out your application, every web app will have its own copy of In-Memory Cache. A request from a browser can arrive on any of the available web app instances. It is necessary that the cached data is consistent across the web app instances.
In-Memory Cache
In-Memory Cache stores data in the memory of Web Server, where a web application hosted and provided cache support for it. It isn’t meant to be hosted individually isolated server. If hosted on a server, the lag between the request for getting the cached objects and getting the response back defies the purpose of having an In-Memory Cache.
Second Level of Cache
Though it’s not necessary, having a Second-Level of cache storage helps reducing database trips. As the In-Memory Cache inside app instances isolated, they may turn to the database for the requested data when evicted from on-memory. A Second-Level Cache can help to reduce those database requests, ensuring reliable faster responses.
Redis
Redis is an open source (BSD licensed), In-memory data structure store, used as a database, cache and message broker. It supports various data structures such as Strings, Hashes, Lists, Sets etc.
Redis is a NoSQL database and extremely fast, and is currently being used by Twitter, GitHub, Weibo, Pinterest, Snapchat, StackOverflow, Flickr, and a lot more other companies. Redis seemed like the best choice for us as a Second-Level cache server. We’re using Azure Cache for Redis as our Redis Server.
In Document360, we use ASP.NET Core In-Memory Cache as first-level cache and Redis as a second-level cache.
Let’s get into the implementation details. The picture below shows the data flow for getting and setting the data having two levels of cache storage. It also shows how we delete the keys on data update.
 Components in the picture
Components in the picture
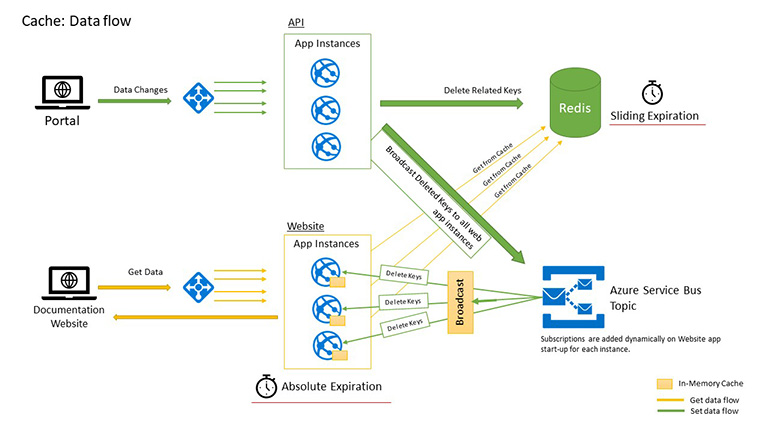 Components in the picture
Components in the picture- Load Balancers – balances and routes the requests among web app instances.
- API Apps – served administration portal and handles data update.
- Documentation Apps – serves documentation websites.
- In-Memory Cache – resides in documentation apps as a first level cache.
- Redis Cache – the second level cache.
- Azure Service Bus Topic/Subscriptions – enables the broadcast of messages to web apps.
Redis Pub/Sub proved as unreliable for us
Redis itself has a pub/sub mechanism which comes out of the box. Our first implementation done was based on the Redis pub/sub as well, but we started having trouble with the receiver later. We used StackExchange. Redis for handling Redis Operations and listening to a subscription. The listener was working fine for the first couple of hours, but gone unresponsive without a reason. We tried to troubleshoot but couldn’t find any legit working solution.
Later, while troubleshooting and exploring the solutions we found that Redis does absolutely not provide any guaranteed delivery for the publish-and-subscribe traffic.
So, we had to turn to Azure Service Bus Topics/Subscription for messaging pub/sub. We knew it’s reliable as we have built serverless360.com, where you can manage and monitor the Azure Serverless Service with very less effort. We use Azure Service Bus Topic/Subscriptions in-and-out for most of the messaging requirements.
Let’s look at each side of the data flow:
Flow #1 Get Data
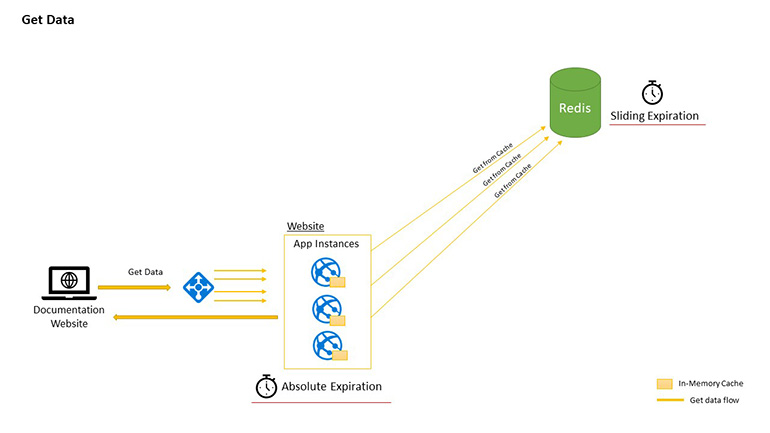
The request for data arrives at the web app. Web app first checks if the data-key is available in In-Memory Cache. Data returns from here if found, otherwise it checks for the data key in the second-level cache (Redis). If found, it stores the data into In-memory for future access and returns the data back to the client. Only in case, the data key is not found in Second level cache, the request will get the data from the original data source (e.g. Database).
While getting data from the source, if data is found, it first stores the data in Redis and then stores the data in In-Memory Cache. And then the data returns to the client.
Flow #2 Set Data
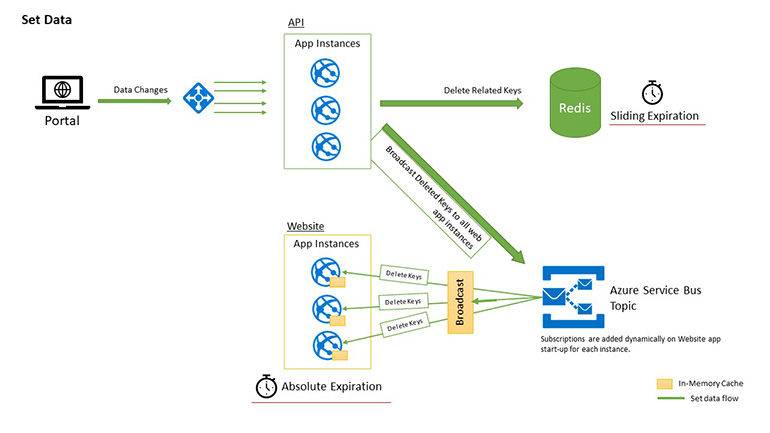
When some of the data modified from the API, it first deletes the corresponding data key(s) on the Second Level cache and then it sends deleted key(s) to a message-broadcaster (in our case it is Azure Service Bus Topic).
For every single web app instance which serves the data – we add a subscription dynamically to the configured topic. As soon the message arrives at the Topic – broadcasts to all the active subscribers (web apps serving the data) and they delete the keys received.
On the next request for the same data, it simply fetches the fresh data from the data source and stores it in Redis. Then, In-Memory Cache of the processing app instance and then returns the data back to the client.
Further – If a request arrives on another app instance – it will get the data from the Redis as set by the first request on first app instance already.
Lessons Learned
Implementing a second-level cache is troublesome if configuration not done properly. We’ve learned it the hard way and would love to share them with you. Always keep the following points in mind:
- Use a “lock” object while updating an In-memory cache
- Keep the In-Memory Cache objects on Absolute Expiration
- Keep the second-level cache objects on Sliding Expiration
- Keep the expiration time of In-Memory Cache objects, lesser than second-level cache objects.
In-Memory Cache objects should set to absolute expiration because they might get out of sync if the data requested from the application but doesn’t change till the duration of the second-level cache object expires. In this scenario, the second-level cache object will evict at the expiration time, but the data will remain in In-Memory Cache (“sliding” due to sliding-expiration).
Expiring the In-memory objects at an absolute time keeps the data in sync. As the In-memory cache object expires, it would refresh from the second-level cache. The second-level cache object will get its expiration increased (due to sliding expiration) and will remain there at-least until In-Memory Cache expires. This arrangement keeps the data in cache afresh across the app instances.